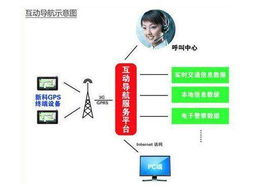
在數(shù)字化與智能化高度滲透的今天,GPS導(dǎo)航儀早已超越了簡(jiǎn)單的指路工具范疇,演變?yōu)榧珳?zhǔn)定位、智能規(guī)劃、生活服務(wù)于一體的移動(dòng)智能終端。尤其是一些身懷‘過(guò)人絕技’的特色便攜式產(chǎn)品,憑借其專(zhuān)精的功能、出色的便攜性以及深度的網(wǎng)絡(luò)技術(shù)服務(wù),正成為戶(hù)外愛(ài)好者、專(zhuān)業(yè)司機(jī)和科技發(fā)燒友的新寵。本文將為您導(dǎo)購(gòu)幾類(lèi)特色便攜GPS導(dǎo)航儀,并深入解讀其背后的網(wǎng)絡(luò)技術(shù)服務(wù)如何提升用戶(hù)體驗(yàn)。
一、特色便攜GPS導(dǎo)航儀核心類(lèi)型導(dǎo)購(gòu)
- 戶(hù)外探險(xiǎn)全能王:多星系統(tǒng)與堅(jiān)固三防
- 核心絕技:這類(lèi)導(dǎo)航儀通常支持GPS、GLONASS、北斗乃至伽利略等多重衛(wèi)星系統(tǒng),確保在深山、峽谷等復(fù)雜環(huán)境下依然能快速鎖定信號(hào),定位精度極高。機(jī)身具備IPX7級(jí)以上防水、防震、防塵能力,配備高亮度陽(yáng)光下可視屏幕和超長(zhǎng)續(xù)航電池。
- 代表場(chǎng)景:徒步、登山、越野、航海。它們不僅能記錄軌跡、標(biāo)注航點(diǎn),更可預(yù)裝專(zhuān)業(yè)等高線(xiàn)地圖,提供高度、氣壓、氣溫等關(guān)鍵環(huán)境數(shù)據(jù)。
- 選購(gòu)要點(diǎn):關(guān)注衛(wèi)星系統(tǒng)支持?jǐn)?shù)量、電池續(xù)航(最好支持充電寶補(bǔ)給)、地圖擴(kuò)展能力以及傳感器的豐富度(如氣壓計(jì)、電子羅盤(pán))。
- 專(zhuān)業(yè)物流好幫手:大屏智能與車(chē)隊(duì)管理
- 核心絕技:針對(duì)商用車(chē)隊(duì)及職業(yè)司機(jī),這類(lèi)設(shè)備通常擁有較大尺寸的觸控屏,運(yùn)行定制化的智能操作系統(tǒng)。其核心在于與后臺(tái)網(wǎng)絡(luò)服務(wù)的深度整合,支持實(shí)時(shí)路況、電子眼預(yù)警、智能路徑規(guī)劃(規(guī)避限行、節(jié)省成本),并能將車(chē)輛位置、行駛數(shù)據(jù)實(shí)時(shí)上傳至管理平臺(tái)。
- 代表場(chǎng)景:長(zhǎng)途貨運(yùn)、網(wǎng)約車(chē)、出租車(chē)、企業(yè)車(chē)隊(duì)管理。
- 選購(gòu)要點(diǎn):屏幕清晰度與操作流暢度、網(wǎng)絡(luò)連接穩(wěn)定性(4G/5C)、后臺(tái)管理功能的強(qiáng)大與否(如車(chē)輛監(jiān)控、油耗分析、駕駛行為評(píng)估)以及配套服務(wù)的年費(fèi)合理性。
- 經(jīng)典便攜經(jīng)濟(jì)款:專(zhuān)注導(dǎo)航與離線(xiàn)可用
- 核心絕技:剝離花哨功能,回歸導(dǎo)航本質(zhì)。這類(lèi)設(shè)備體積小巧,價(jià)格親民,預(yù)裝詳細(xì)的離線(xiàn)地圖數(shù)據(jù)。無(wú)需持續(xù)依賴(lài)蜂窩網(wǎng)絡(luò),一次性購(gòu)買(mǎi)后長(zhǎng)期使用,無(wú)后續(xù)流量費(fèi)用擔(dān)憂(yōu)。路線(xiàn)計(jì)算能力強(qiáng),界面簡(jiǎn)潔直觀(guān)。
- 代表場(chǎng)景:日常通勤、自駕游、對(duì)網(wǎng)絡(luò)依賴(lài)度低的地區(qū)旅行,或作為車(chē)載/手機(jī)導(dǎo)航的可靠備用。
- 選購(gòu)要點(diǎn):離線(xiàn)地圖的更新頻率與便捷性(是否提供終身免費(fèi)更新)、操作界面的人性化程度、搜星速度以及屏幕在強(qiáng)光下的表現(xiàn)。
二、網(wǎng)絡(luò)技術(shù)服務(wù):導(dǎo)航儀的“智慧大腦”
現(xiàn)代特色GPS導(dǎo)航儀的“過(guò)人絕技”,很大程度上得益于其背后強(qiáng)大的網(wǎng)絡(luò)技術(shù)服務(wù)支撐。這些服務(wù)已從簡(jiǎn)單的數(shù)據(jù)更新,演變?yōu)橐粋€(gè)完整的云端生態(tài)系統(tǒng):
- 實(shí)時(shí)動(dòng)態(tài)數(shù)據(jù)服務(wù):這是最基礎(chǔ)也最關(guān)鍵的服務(wù)。通過(guò)網(wǎng)絡(luò)(通常是蜂窩移動(dòng)網(wǎng)絡(luò)或后續(xù)的Wi-Fi同步),設(shè)備可以獲取:
- 實(shí)時(shí)交通路況(RDS-TMC或在線(xiàn)更新):動(dòng)態(tài)顯示擁堵、事故、施工信息,并主動(dòng)重新規(guī)劃路線(xiàn)。
- 在線(xiàn)興趣點(diǎn)(POI)搜索與更新:查找最新商戶(hù)、加油站、停車(chē)場(chǎng),并顯示用戶(hù)評(píng)價(jià)、營(yíng)業(yè)時(shí)間等。
- 天氣信息集成:為出行提供沿途天氣預(yù)警。
- 云端智能計(jì)算與同步:
- 智能路徑規(guī)劃:結(jié)合實(shí)時(shí)路況、歷史大數(shù)據(jù)、車(chē)輛類(lèi)型(如貨車(chē)限高限重),在云端計(jì)算出最優(yōu)路徑,再下發(fā)至設(shè)備。
- 云端存儲(chǔ)與同步:用戶(hù)的收藏地點(diǎn)、行駛軌跡、設(shè)備設(shè)置可以同步至云端賬戶(hù),實(shí)現(xiàn)多設(shè)備間無(wú)縫切換,數(shù)據(jù)永不丟失。
- ADAS高級(jí)駕駛輔助信息:通過(guò)網(wǎng)絡(luò)更新,提供車(chē)道級(jí)導(dǎo)航、復(fù)雜路口放大、交通標(biāo)志識(shí)別等增強(qiáng)信息。
- 增值與互聯(lián)服務(wù):
- 安防與救援服務(wù):部分設(shè)備配備SOS緊急按鈕,觸發(fā)后可自動(dòng)將精準(zhǔn)位置發(fā)送至預(yù)設(shè)聯(lián)系人或救援中心。
- 車(chē)輛互聯(lián)與診斷:通過(guò)OBD接口或內(nèi)置傳感器,可將車(chē)輛診斷信息、胎壓數(shù)據(jù)等上傳,提供保養(yǎng)提醒、故障預(yù)警。
- 社交與共享功能:允許用戶(hù)上傳、分享自己的旅行軌跡和路書(shū),形成社區(qū)化的出行生態(tài)。
三、與選購(gòu)建議
選擇一款‘身懷絕技’的便攜GPS導(dǎo)航儀,關(guān)鍵在于明確核心需求:
- 如果你是戶(hù)外探險(xiǎn)家,應(yīng)優(yōu)先選擇多星系統(tǒng)、三防耐用、傳感器豐富的專(zhuān)業(yè)戶(hù)外機(jī)型,網(wǎng)絡(luò)服務(wù)可能更側(cè)重于事后軌跡分析和地圖更新。
- 如果你是職業(yè)司機(jī)或車(chē)隊(duì)管理者,應(yīng)選擇大屏智能、網(wǎng)絡(luò)連接穩(wěn)定、與強(qiáng)大車(chē)隊(duì)管理平臺(tái)深度整合的機(jī)型,網(wǎng)絡(luò)服務(wù)的實(shí)時(shí)性與管理功能至關(guān)重要。
- 如果你追求穩(wěn)定可靠、經(jīng)濟(jì)實(shí)惠,一款離線(xiàn)地圖詳盡、更新方便的經(jīng)典便攜機(jī)型是最佳選擇,其對(duì)網(wǎng)絡(luò)服務(wù)的依賴(lài)度最低。
無(wú)論如何,在購(gòu)買(mǎi)時(shí),請(qǐng)務(wù)必詳細(xì)了解設(shè)備所包含的網(wǎng)絡(luò)服務(wù)內(nèi)容、收費(fèi)標(biāo)準(zhǔn)(是否有隱藏年費(fèi))、以及服務(wù)商的可靠性與數(shù)據(jù)更新頻率。一臺(tái)硬件出色的導(dǎo)航儀,搭配持續(xù)、精準(zhǔn)、智能的網(wǎng)絡(luò)服務(wù),才能真正做到‘慧’指前程,讓你的每一次出行都安心、高效且充滿(mǎn)樂(lè)趣。